로스 산토스는 찬란한 햇빛을 받으며 거대하게 뻗은 대도시입니다. 이곳에는 감동적인 인간 승리를 이뤄낸 사람들과 수많은 아이돌 스타, 퇴물이 되어가는 유명인사 등, 한때는 서구 세계의 부러움을 한몸에 받았던 사람들이 경제 불황과 싸구려 리얼리티 TV 시대에 살아남으려 발버둥치고 있습니다.
이런 혼란의 시기에 세 명의 서로 다른 범죄자들이 생존과 성공의 기회를 잡고자 계획을 세웁니다. 별 볼 일 없는 건달 프랭클린은 제대로 된 기회를 잡아 큰돈을 벌고 싶어합니다. 화려한 전과자였던 마이클은 은퇴 후 지루한 생활을 보내다가 다시 화려한 시절을 꿈꿉니다. 싸구려 마약에 찌든 난폭한 미치광이 트레버는 큰 건수를 노리고 있습니다. 막다른 길에 내몰린 이들은 각자의 모든 것을 걸고 일생일대의 대담하고 위험한 사건을 잇달아 저지릅니다.
역대 최고로 거대하고 역동적이며 다양한 오픈 월드 안에서 Grand Theft Auto V는 새로운 방식으로 이야기 전개와 게임 플레이를 혼합했습니다. 플레이어는 게임의 세 주인공의 인생에 들락날락하면서 서로 교차하는 이야기를 모두 플레이하게 됩니다.
예를 들어 선행 스킬 순서가스파크 → 라이트닝 볼트 → 썬더일때, 썬더를 배우려면 먼저 라이트닝 볼트를 배워야 하고, 라이트닝 볼트를 배우려면 먼저 스파크를 배워야 합니다.
위 순서에 없는 다른 스킬(힐링 등)은 순서에 상관없이 배울 수 있습니다. 따라서스파크 → 힐링 → 라이트닝 볼트 → 썬더와 같은 스킬트리는 가능하지만,썬더 → 스파크나라이트닝 볼트 → 스파크 → 힐링 → 썬더와 같은 스킬트리는 불가능합니다.
선행 스킬 순서 skill과 유저들이 만든 스킬트리1를 담은 배열 skill_trees가 매개변수로 주어질 때, 가능한 스킬트리 개수를 return 하는 solution 함수를 작성해주세요.
skill
skill_trees
return
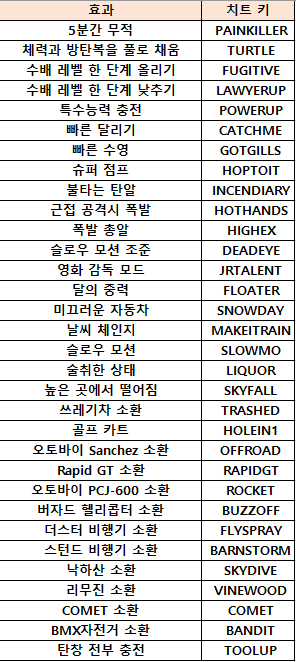
CBD
[BACDE,CBADF,AECB,BDA]
2
import java.util.*;
class Solution {
public int solution(String skill, String[] skill_trees) {
int answer = 0;
ArrayList<String> skillTrees = new ArrayList<String>(Arrays.asList(skill_trees));
//ArrayList<String> skillTrees = new ArrayList<String>();
Iterator<String> it = skillTrees.iterator();
while (it.hasNext()) {
if (skill.indexOf(it.next().replaceAll("[^" + skill + "]", "")) != 0) {
it.remove();
}
}
answer = skillTrees.size();
return answer;
}
}
*Practice 3 : 큰 수 만들기
어떤 숫자에서 k개의 수를 제거했을 때 얻을 수 있는 가장 큰 숫자를 구하려 합니다.
예를 들어, 숫자 1924에서 수 두 개를 제거하면 [19, 12, 14, 92, 94, 24] 를 만들 수 있습니다. 이 중 가장 큰 숫자는 94 입니다.
문자열 형식으로 숫자 number와 제거할 수의 개수 k가 solution 함수의 매개변수로 주어집니다. number에서 k 개의 수를 제거했을 때 만들 수 있는 수 중 가장 큰 숫자를 문자열 형태로 return 하도록 solution 함수를 완성하세요.
number
k
return
1924
2
94
1231234
3
3234
4177252841
4
775841
import java.util.Stack;
class Solution {
public String solution(String number, int k) {
char[] result = new char[number.length() - k];
Stack<Character> stack = new Stack<>();
for (int i=0; i<number.length(); i++) {
char c = number.charAt(i);
while (!stack.isEmpty() && stack.peek() < c && k-- > 0) {
stack.pop();
}
stack.push(c);
}
for (int i=0; i<result.length; i++) {
result[i] = stack.get(i);
}
return new String(result);
}
}
*Practice 4: 카펫
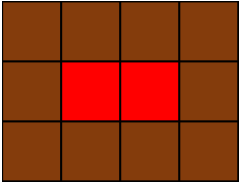
Leo는 카펫을 사러 갔다가 아래 그림과 같이 중앙에는 빨간색으로 칠해져 있고 모서리는 갈색으로 칠해져 있는 격자 모양 카펫을 봤습니다.
Leo는 집으로 돌아와서 아까 본 카펫의 빨간색과 갈색으로 색칠된 격자의 개수는 기억했지만, 전체 카펫의 크기는 기억하지 못했습니다.
Leo가 본 카펫에서 갈색 격자의 수 brown, 빨간색 격자의 수 red가 매개변수로 주어질 때 카펫의 가로, 세로 크기를 순서대로 배열에 담아 return 하도록 solution 함수를 작성해주세요.
brown
red
return
10
2
[4, 3]
8
1
[3, 3]
24
24
[8, 6]
class Solution {
public int[] solution(int brown, int red) {
int[] answer = new int[2];
int red_x, red_y;
for(int i = 1; i<=red; i++){
if(red % i == 0){
red_y = i;
red_x = red/i;
if(brown == 4 + red_x * 2 + red_y * 2){
answer[0] = red_x + 2;
answer[1] = red_y + 2;
return answer;
}
}
}
return answer;
}
}
class Solution {
public int[] solution(int brown, int red) {
for(int i=1; i<=red; i++) {
if(red%i==0 && (red/i+i)*2+4==brown) {
return new int[] {red/i+2, i+2};
}
}
return null;
}
}
*Practice 5: 짝지어 제거하기
짝지어 제거하기는, 알파벳 소문자로 이루어진 문자열을 가지고 시작합니다. 먼저 문자열에서 같은 알파벳이 2개 붙어 있는 짝을 찾습니다. 그다음, 그 둘을 제거한 뒤, 앞뒤로 문자열을 이어 붙입니다. 이 과정을 반복해서 문자열을 모두 제거한다면 짝지어 제거하기가 종료됩니다. 문자열 S가 주어졌을 때, 짝지어 제거하기를 성공적으로 수행할 수 있는지 반환하는 함수를 완성해 주세요. 성공적으로 수행할 수 있으면 1을, 아닐 경우 0을 리턴해주면 됩니다.
예를 들어, 문자열 S =baabaa라면
baabaa →bbaa →aa→
의 순서로 문자열을 모두 제거할 수 있으므로 1을 반환합니다.
s
result
baabaa
1
cdcd
0
import java.util.*;
class Solution
{
public int solution(String s)
{
// 문자열을 캐릭터 배열로 변환
char[] c = s.toCharArray();
ArrayList<Character> list = new ArrayList<>();
// 캐릭터를 하나씩 리스트에 삽입
for(char _c : c){
Add(list, _c);
}
// 만약 리스트가 비었다면 짝지거 제거 완료
if(list.isEmpty()){
return 1;
}
else {
return 0;
}
}
// 리스트에 캐릭터 하나씩 삽입하는 함수
public static void Add(ArrayList _list, char _c){
_list.add(_c);
// 만약 리스트의 길이가 2보다 크고 && 마지막 두 원소가 같은 캐릭터라면
if(_list.size() > 1 && (_list.get(_list.size() - 2) == _list.get(_list.size() - 1))){
// 마지막 두 원소 제거
_list.remove(_list.size() - 1);
_list.remove(_list.size() - 1);
}
}
}
*Practice 6: 숫자의 표현
Finn은 요즘 수학공부에 빠져 있습니다. 수학 공부를 하던 Finn은 자연수 n을 연속한 자연수들로 표현 하는 방법이 여러개라는 사실을 알게 되었습니다. 예를들어 15는 다음과 같이 4가지로 표현 할 수 있습니다.
1 + 2 + 3 + 4 + 5 = 15
4 + 5 + 6 = 15
7 + 8 = 15
15 = 15
자연수 n이 매개변수로 주어질 때, 연속된 자연수들로 n을 표현하는 방법의 수를 return하는 solution를 완성해주세요.
n
result
15
4
public class Expressions {
public int expressions(int num) {
int answer = 0;
int result = 0;
for(int i = 1; i<=num; i++){
for(int j = i; j<=num; j++){
result += j;
if(result == num){
++answer;
} else if(result > num){
result = 0;
break;
}
}
}
return answer;
}
public static void main(String args[]) {
Expressions expressions = new Expressions();
// 아래는 테스트로 출력해 보기 위한 코드입니다.
System.out.println(expressions.expressions(6));
}
}
*Practice 7: 가장 큰 정사각형 찾기
1와 0로 채워진 표(board)가 있습니다. 표 1칸은 1 x 1 의 정사각형으로 이루어져 있습니다. 표에서 1로 이루어진 가장 큰 정사각형을 찾아 넓이를 return 하는 solution 함수를 완성해 주세요. (단, 정사각형이란 축에 평행한 정사각형을 말합니다.)